


If you're pressed for time or not particularly keen on coding, you can try a live demo at doXtractor.com.
![]()
This article offers a quick and straightforward method for leveraging the PaLM 2 API to extract knowledge and ask questions from text, specifically PDF documents. The design prioritizes clarity and limits API calls by making strategic use of open-source frameworks and libraries, including:
- Langchain framework for developing applications powered by language models.
- FAISS library for conducting efficient similarity searches.
- Hugging Face Instructor embedding model.
- PyPDF2 for extracting text from PDF files.
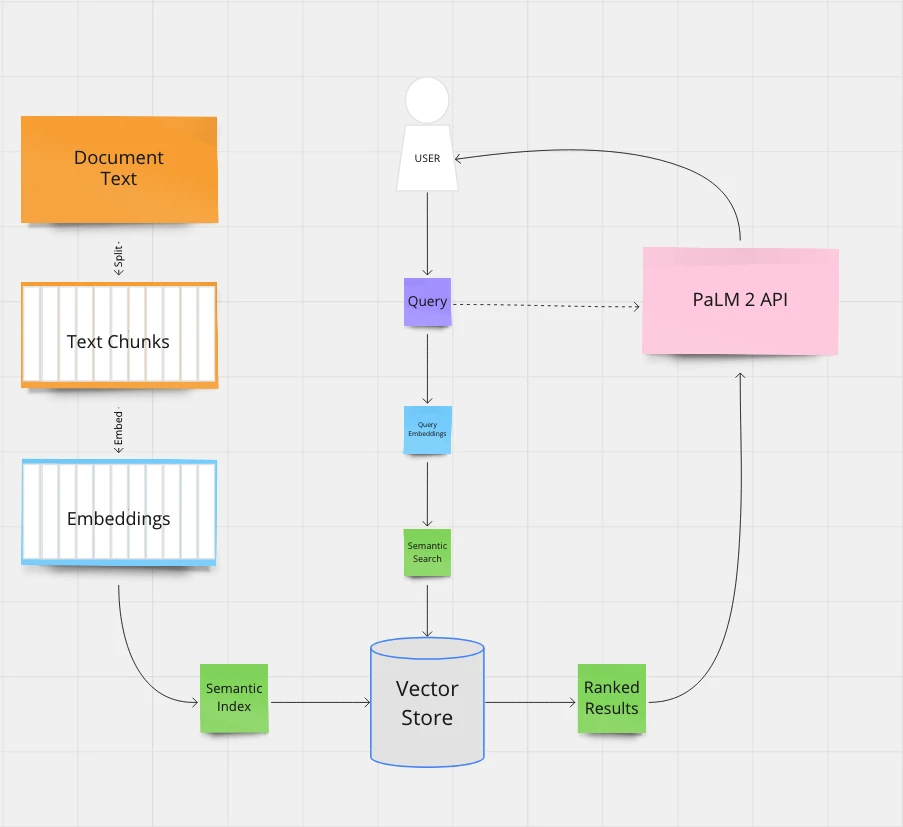
The architecture is simple:
- First, we convert PDFs into text and segment them into manageable chunks to fit the language model's input requirements.
- Next, we calculate embeddings for all these chunks, storing them as a Semantic Index within a Knowledge Base (Vector Store).
- When users submit queries, we compute embeddings for their input and conduct a Semantic Similarity search against the Vector Store.
- Finally, we send the query and the ranked results to PaLM 2 and retrieve your answers.
Before you dive into the process, there are a couple of important points to keep in mind:
- GPU Requirement: Utilizing the formidable hkunlp/instructor-xl embedding model is highly recommended with a GPU, unless you have ample time to spare. To access one, simply change the runtime type to "T4 GPU" hardware accelerator on Google Colaboratory.
- Alternative Approach: If you prefer not to use a GPU or don't have access to one, you can opt for the alternative method of "embeddings = GooglePalmEmbeddings()." This choice, however, may result in additional API calls to Google Cloud Platform (GCP).
Let's begin..
Before you get started, you'll need a Google PaLM API key. Head to https://makersuite.google.com/, sign up with your Google account, and click "Get an API key". Once you have the key, you can start using the API.
If you've already signed up for Google MakerSuite, head over to https://developers.generativeai.google/tutorials/setup and grab an API key, enter it below to load it in a system environment variable.
Load your API key..
Copy and paste your Google API Key here. It looks something like this "ANzaSyAx2ldanqSJCwnaslkjvvBkeCe7l84O0Gs"
export GOOGLE_API_KEY=[YOUR API KEY HERE]
Install, download and load stuff..
You saw this coming right? You'll have to install some required packages and dependencies..
pip install -q langchain==0.0.297 \
PyPDF2==3.0.1 \
faiss-cpu==1.7.4 \
google-generativeai==0.1.0 \
InstructorEmbedding==1.0.1 \
sentence_transformers==2.2.2
Now, it's time to download a PDF file. Feel free to replace this with a document of your choice. Personally, I'd like to try the US Declaration of Independence.
wget https://www.uscis.gov/sites/default/files/document/guides/M-654.pdf
Bring your friends.. Most are from the Langchain family, which includes a diverse array of models and libraries at your disposal, empowering you to create a wide range of language-based
from PyPDF2 import PdfReader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import FAISS
from langchain.llms import GooglePalm
from langchain.chains.question_answering import load_qa_chain
from langchain.embeddings.huggingface import HuggingFaceInstructEmbeddings
# from langchain.embeddings import GooglePalmEmbeddings # If no GPU/time.
The Hugging Face InstructEmbeddings model is quite substantial and may require some time for the initial download and setup. However, it's important to note that this process is a one-time requirement.
embeddings_model_name = "hkunlp/instructor-xl"
embeddings = HuggingFaceInstructEmbeddings(model_name=embeddings_model_name,model_kwargs={"device": "cuda"})
# Cloud based embedding alternative:
# embeddings = GooglePalmEmbeddings()
Let's do this..
We are now prepared to begin processing our document:
- Extract text from the PDF file.
- Split the text into chunks of 2000 tokens each.
- Use Hugging Face Instructor model to generate embeddings from these text chunks.
- Save our Semantic Index in a Vector Store.
pdf = "M-654.pdf"
if pdf:
# Extract text from each page
pdf_reader = PdfReader(pdf)
text = ""
for page in pdf_reader.pages:
text += page.extract_text()
# Split text into chunks
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=2000,
chunk_overlap=200,
length_function=len
)
chunks = text_splitter.split_text(text=text)
# Embed chunks and store them in a Vector Store
VectorStore = FAISS.from_texts(chunks, embedding=embeddings)
Ready to play? Alright, let's ask an interesting question:
query = "You are Larry the Cable Guy, a comedian. Write a script for a standup comedy monologue about this document"
Now, our next step involves embedding our query using the same model and initiating a similarity search against our VectorStore. Subsequently, we will leverage the capabilities of Langchain to transmit the resulting matches, along with our query, to the Google PaLM 2 API to obtain a response.
if query:
docs = VectorStore.similarity_search(query=query, k=3)
llm = GooglePalm()
llm.temperature = 0.1 # Increase for more creativity [0.0-1.0]
chain = load_qa_chain(llm=llm, chain_type="stuff")
response = chain.run(input_documents=docs, question=query)
print(response)**Larry the Cable Guy:** Hey, y'all! I'm Larry the Cable Guy, and I'm here to talk to you about the Constitution. Now, I ain't no lawyer, but I know a thing or two about this document. It's the foundation of our country, and it's important that we all know what it says. So, let's start with the first line: "We the People of the United States, in Order to form a more perfect Union, establish Justice, insure domestic Tranquility, provide for the common defence, promote the general Welfare, and secure the Blessings of Liberty to ourselves and our Posterity, do ordain and establish this Constitution for the United States of America." Now, that's a mouthful, ain't it? But what it's saying is that we, the people, are the ones who make the rules. We're the ones who decide what kind of country we want to live in. And the Constitution is the document that sets out those rules. So, if you don't like the way things are going, you can change them. That's what the Constitution is all about. It's a living document, and it's meant to be changed as the times change. But the one thing that can never change is the fact that we, the people, are the ones who are in charge. We're the ones who make the rules. And that's what makes this country so great. So, next time you're feeling down about the state of the world, just remember the Constitution. It's a reminder that we, the people, are the ones who are in control. And that's something to be proud of. **Audience:** (cheers)
And there you have it! Feel free to explore various questions and experiment with the multitude of ways available to extract, summarize, simplify, or export information in your preferred style. As an extra challenge, see if you can transform the document into a poem in your favorite poetic style or craft it into a song reminiscent of Justin Timberlake. Enjoy the creative journey!




